 Download
Download
Kaiser, C., Kaiser, J., Schallner, R., Manewitsch, V. & Rau, L. (2026). Leaving Insight to Digital Twins? Promise, Progress and Limits of Synthetic Respondents. NIM Marketing Intelligence Review, 18(1), 48-53. https://doi.org/10.2478/nimmir-2026-0008
Digitale Zwillinge als Insight-Quelle: Potenzial, Fortschritt und Grenzen synthetischer Befragter
Marketingteams brauchen schnelle und verlässliche Einblicke in Einstellungen und Vorlieben von Konsumenten. Klassische Umfragen liefern diese Einblicke jedoch immer schlechter: Sie sind teuer, dauern lange und immer weniger Menschen nehmen daran teil. Deshalb wächst das Interesse an Alternativen, die günstiger sind, sich leichter skalieren lassen und auch unter Zeit- und Budgetdruck Erkenntnisse liefern können. Neue Fortschritte bei großen Sprachmodellen (LLMs) haben einen solchen Ansatz möglich gemacht: Ein LLM beantwortet Fragebögen so, als wäre es ein Konsument mit einem bestimmten demografischen Profil. Auf diese Weise entstehen synthetische Datensätze aus virtuellen Befragten – sogenannte Silicon Samples. Dieser Ansatz findet zunehmend Aufmerksamkeit in der professionellen Marktforschung. Wenn er funktioniert, könnten synthetische Befragte klassische Umfragen ergänzen oder für schnelle Simulationen genutzt werden, etwa um frühe Konsumentenreaktionen oder Konzepte zu testen. Die bisherigen Ergebnisse sind jedoch uneinheitlich, und die meisten Validierungen stammen nicht aus dem Marketing. Es ist noch unklar, inwieweit LLMs tatsächliche Konsumentenentscheidungen, Stimmungen und realistische Unterschiede zwischen Personen zuverlässig abbilden können. Wir stellen eine Studie mit synthetischen Befragten vor, in der zwei unterschiedliche Befragungsformate in einem realistischen Marketing-Funnel-Szenario getestet wurden (Box 1).

Wie gut sind synthetische Befragte im Vergleich zu echten Personen?
Insgesamt sagten die synthetischen Antworten individuelle Entscheidungen deutlich besser voraus als es bei reinem Raten zu erwarten wäre. Allgemeine Trends – etwa die stärkere Bevorzugung bekannter Marken – wurden korrekt erkannt. Gleichzeitig zeigten sich klare systematische Abweichungen: Die synthetischen Befragten bewerteten Marken insgesamt zu positiv, besonders bekannte Marken, und unterschieden sich untereinander deutlich weniger als echte Menschen.
> Richtige Trends, überhöhte Wahrscheinlichkeiten und Bewertungen
Wie erwartet wählten echte Teilnehmer im Marketing-Funnel deutlich häufiger bekannte als unbekannte Marken. Dieses Grundmuster wurde von den synthetischen Daten korrekt nachgebildet. Allerdings überschätzten die synthetischen Befragten die Auswahlwahrscheinlichkeit bekannter Marken deutlich (siehe Abbildung 1). Im Durchschnitt stimmten synthetische und reale Entscheidungen in 79 % der Fälle überein. Das zeigt: LLM-basierte Befragte erfassen die Richtung der Effekte, überschätzen aber systematisch, wie stark Konsumenten sich tatsächlich für eine Marke entscheiden. Ein ähnliches Bild ergab sich bei den Markenbewertungen. Echte Teilnehmer bewerteten bekannte Marken besser als weniger bekannte, und auch hier trafen die synthetischen Daten den Trend. Die absoluten Bewertungen fielen jedoch durchweg zu positiv aus – mit der stärksten Verzerrung zugunsten bekannter Marken. Über alle Marken hinweg wichen die synthetischen Bewertungen auf der 7-stufigen Skala im Schnitt um 1,2 Punkte von den realen Bewertungen ab.
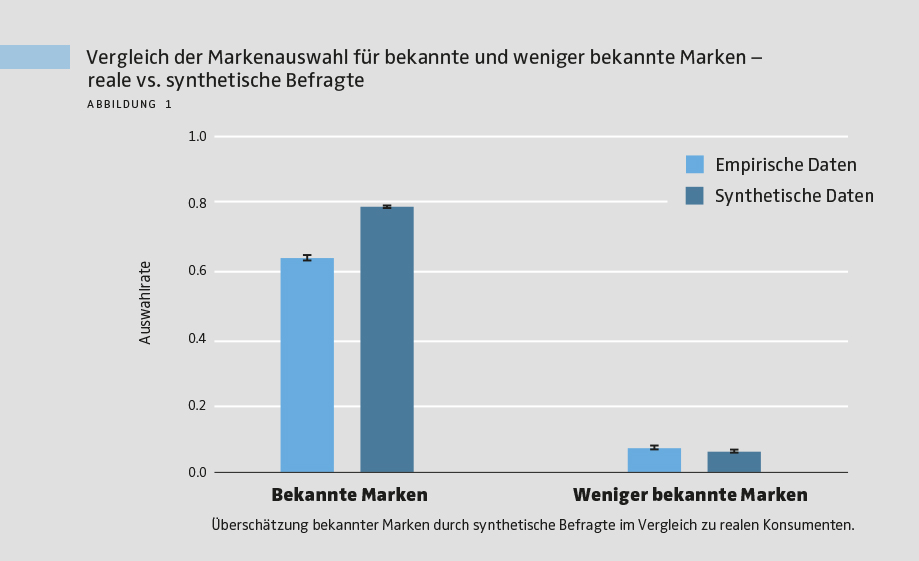
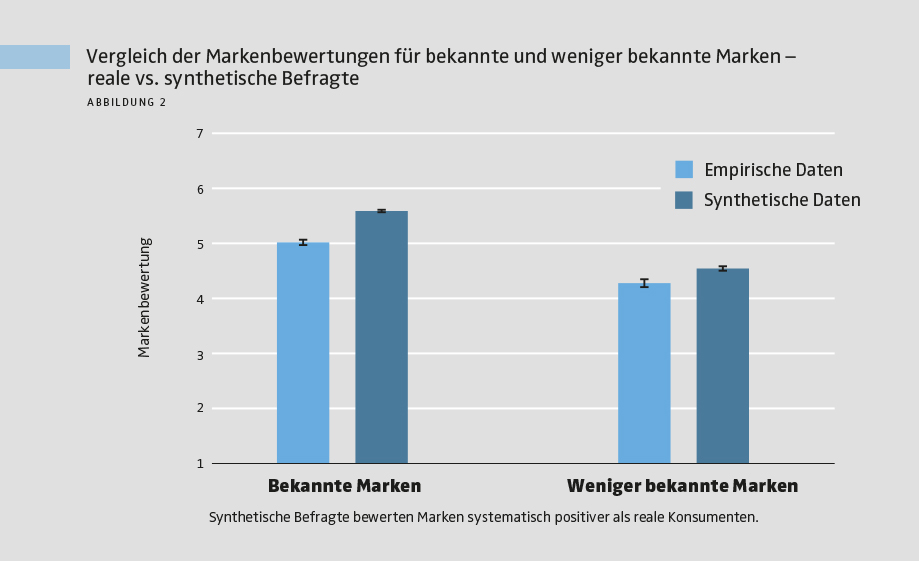
> Geringere Vielfalt als bei echten Antworten
Durchschnittswerte sind wichtig, aber für Marktforschung ist auch entscheidend, wie stark sich einzelne Konsumenten in ihren Meinungen unterscheiden. Genau hier zeigen sich klare Grenzen synthetischer Daten. Beim Vergleich der Antwortverteilungen – sowohl bei der Markenauswahl als auch bei den Markenbewertungen auf der Likert-Skala – waren die synthetischen Antworten deutlich weniger streuend als die realen Antworten. Dieser Effekt war besonders ausgeprägt bei bekannten Marken. Insgesamt zeigt sich: Von LLMs erzeugte Daten bilden zwar typische Antworten ab, unterschätzen aber die tatsächliche Meinungsvielfalt realer Konsumenten. Die Ergebnisse fallen homogener aus, als sie es in der Realität sind.
> Semantische Ähnlichkeitsbewertungen verbessern den Realismus
Der Vergleich der Verteilungen der Markenbewertungen von echten Befragten mit synthetischen Befragten auf Basis der direkten Erhebung auf der Likert-Skala und der semantischen Ähnlichkeitsbewertung zeigt für unsere Umfrage ein klares Muster: Die semantische Ähnlichkeitsbewertung erzeugt eine größere Variabilität als die direkte Erhebung auf der Likert-Skala, was auf einen verbesserten Realismus hindeutet (siehe Abbildung 3). Allerdings werden die Markeneinstellungen immer noch überschätzt und es zeigen sich nach wie vor weniger Schwankungen als bei echten Befragten. Beide synthetischen Methoden unterschätzen die in menschlichen Antworten beobachtete Variabilität, obwohl die semantische Ähnlichkeitsbewertung im Vergleich zur direkten Erhebung auf der Likert-Skala eine teilweise Verbesserung zeigt. Kurz gesagt: Die semantische Ähnlichkeitsbewertung ist eine Verbesserung, aber auch noch kein Ersatz für echte Daten.

Implikationen für die Marktforschung: Sinnvolle Einsatzbereiche synthetischer Daten
Unsere Studie zeigt, dass LLMs mithilfe personalisierter „digitaler Zwillinge“ menschliche Umfrageantworten simulieren können. Der Ansatz hat Potenzial, aber auch klare Grenzen. Synthetische Daten neigen dazu, Antworten zu verallgemeinern oder sozial erwünschte Muster zu zeigen. Dadurch spiegeln sie die feinen Nuancen und die Vielfalt echter Konsumentenmeinungen nur eingeschränkt wider. Der praktische Nutzen liegt derzeit vor allem in Frühphasen-Tests, etwa für Konzept- oder Ideenbewertungen, oder in Anwendungen mit geringerem Risiko. Für Entscheidungen, die präzise Einblicke erfordern, sind echte Umfragedaten weiterhin unverzichtbar.
Ausblick: Wege zur Verbesserung synthetischer Umfragen
LLMs entwickeln sich schnell, und neue Methoden könnten die derzeitigen Einschränkungen synthetischer Umfragedaten verringern. Ein vielversprechender Ansatz ist die hier präsentierte semantische Ähnlichkeitsbewertung (siehe Box 1), bei der das Modell zunächst eine natürliche Textantwort erzeugt, die anschließend auf eine Likert-Skala übertragen wird. So wird die Stärke des Modells in der Textgenerierung genutzt und die Beurteilung ähnelt mehr der durch Menschen. Weitere Verbesserungen könnten erreicht werden, indem mehr persönliche Informationen einbezogen werden – zum Beispiel psychologische Merkmale oder Verhaltensdaten. Externe Kontexte wie Produktbewertungen oder Wirtschaftsindikatoren können auch über Retrieval-Augmented Generation (RAG) inkludiert werden. Insgesamt könnten diese Ansätze dazu beitragen, dass synthetische Daten realistischer werden und die tatsächlichen Einstellungen von Konsumenten besser widerspiegeln.
Effizienz und Ethik in Einklang bringen
KI bietet Markforschern viele Chancen: Sie kann Forschungsprozesse beschleunigen, Kosten senken und große Datenmengen schnell generieren. Gleichzeitig besteht das Risiko, dass Verzerrungen und Übergeneralisierungen die Ergebnisse verfälschen und dann falsche strategische Entscheidungen getroffen werden. Für Konsumenten kann KI ein schnelleres, reaktionsfähigeres Marketing ermöglichen, doch zu starke Vereinfachungen könnten dazu führen, dass Angebote weniger personalisiert oder sogar irrelevant werden. Auf gesellschaftlicher Ebene wirft der zunehmende Einsatz von KI in der Marktforschung auch ethische Fragen auf: Sie kann Stereotype verstärken, Minderheitenmeinungen marginalisieren und traditionelle Aufgaben in der Forschung massiv verändern. Um verantwortungsbewusst Nutzen aus KI zu ziehen, sind daher sorgfältige Kontrolle und neue Kompetenzen erforderlich – damit Erkenntnisse zuverlässig sind, ohne Vorurteile oder Ungleichheiten zu verstärken.
LITERATURHINWEISE
Kaiser, C., Kaiser, J., Manewitsch, V., Rau, L., & Schallner, R. (2025). Simulating human opinions with large language models: Opportunities and challenges for personalized survey data modeling. In Adjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization (pp. 82–86). Association for Computing Machinery. https://doi.org/10.1145/3708319.3733685
Maier, B. F., Aslak, U., Fiaschi, L., Rismal, N., Fletcher, K., Luhmann, C. C., Dow, R., Pappas, K., & Wiecki, T. V. (2025). LLMs reproduce human purchase intent via semantic similarity elicitation of Likert ratings. arXiv:2510.08338. https://arxiv.org/abs/2510.08338
Kaiser, C., Kaiser, J., Schallner, R., Manewitsch, V. & Rau, L. (2026). Leaving Insight to Digital Twins? Promise, Progress and Limits of Synthetic Respondents. NIM Marketing Intelligence Review, 18(1), 48-53. https://doi.org/10.2478/nimmir-2026-0008
Weitere Artikel der MIR-Ausgabe “KI in der Marktforschung”
Hier finden Sie weitere spannende Artikel dieser Ausgabe.









